
-
Python和Excel的交互
-
vlookup函数
-
数据透视表
-
绘图
import numpy as npimport pandas as pdpd.set_option('max_columns', 10)pd.set_option('max_rows', 20)pd.set_option('display.float_format', lambda x: '%.2f' % x) # 禁用科学计数法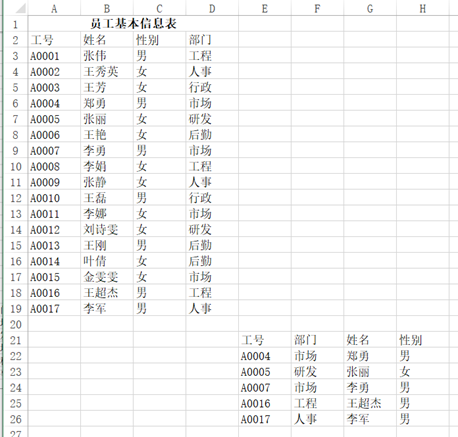
df: 姓名 性别 部门0 A0001 张伟 男 工程1 A0002 王秀英 女 人事2 A0003 王芳 女 行政3 A0004 郑勇 男 市场4 A0005 张丽 女 研发5 A0006 王艳 女 后勤6 A0007 李勇 男 市场7 A0008 李娟 女 工程8 A0009 张静 女 人事9 A0010 王磊 男 行政10 A0011 李娜 女 市场11 A0012 刘诗雯 女 研发12 A0013 王刚 男 后勤13 A0014 叶倩 女 后勤14 A0015 金雯雯 女 市场15 A0016 王超杰 男 工程16 A0017 李军 男 人事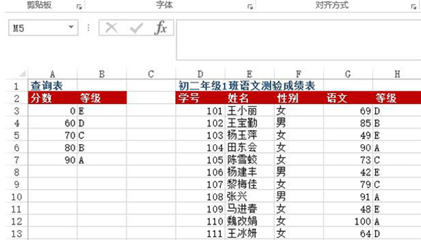
df = pd.read_excel("test.xlsx", sheet_name=0)def grade_to_point(x): if x >= 90: return 'A' elif x >= 80: return 'B' elif x >= 70: return 'C' elif x >= 60: return 'D' else: return 'E'
= df['语文'].apply(grade_to_point)df
: 姓名 性别 语文 等级0 101 王小丽 女 69 D1 102 王宝勤 男 85 B2 103 杨玉萍 女 49 E3 104 田东会 女 90 A4 105 陈雪蛟 女 73 C5 106 杨建丰 男 42 E6 107 黎梅佳 女 79 C7 108 张兴 男 91 A8 109 马进春 女 48 E9 110 魏改娟 女 100 A10 111 王冰研 女 64 D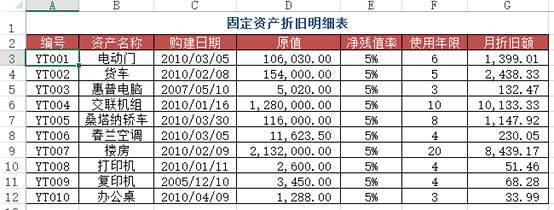

df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')df2 = pd.read_excel("test.xlsx", sheet_name=1) #题目里的sheet1df2.merge(df1[['编号', '月折旧额']], how='left', on='编号')Out[]: 编号 资产名称 月折旧额0 YT001 电动门 13991 YT005 桑塔纳轿车 11472 YT008 打印机 51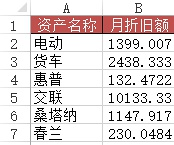
=VLOOKUP(A2&"*", 折旧明细表!$B$2:$G$12, 6, 0)df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表') df3 = pd.read_excel("test.xlsx", sheet_name=3) #含有资产名称简写的表df3['月折旧额'] = 0for i in range(len(df3['资产名称'])): df3['月折旧额'][i] = df1[df1['资产名称'].map(lambda x:df3['资产名称'][i] in x)]['月折旧额']
df3Out[]: 资产名称 月折旧额0 电动 13991 货车 24382 惠普 1323 交联 101334 桑塔纳 11475 春兰 230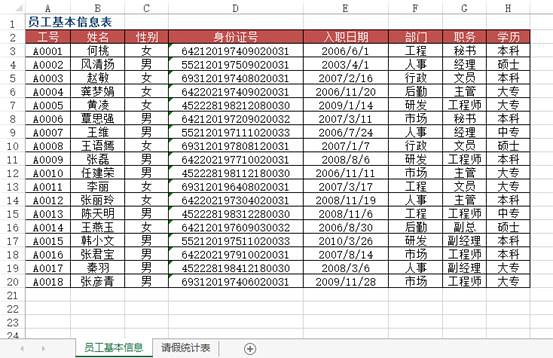
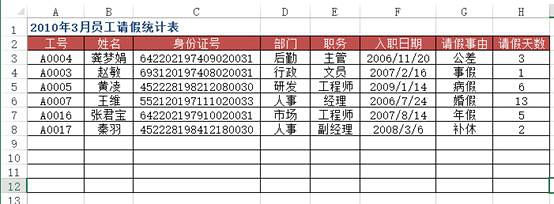
df4 = pd.read_excel("test.xlsx", sheet_name='员工基本信息表')df5 = pd.read_excel("test.xlsx", sheet_name='请假统计表')df5.merge(df4[['工号', '姓名', '部门', '职务', '入职日期']], on='工号')Out[]: 工号 姓名 部门 职务 入职日期0 A0004 龚梦娟 后勤 主管 2006-11-201 A0003 赵敏 行政 文员 2007-02-162 A0005 黄凌 研发 工程师 2009-01-143 A0007 王维 人事 经理 2006-07-244 A0016 张君宝 市场 工程师 2007-08-145 A0017 秦羽 人事 副经理 2008-03-06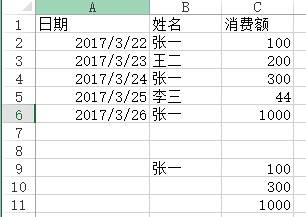
=VLOOKUP(B$9&ROW(A1),IF({1,0},$B$2:$B$6&COUNTIF(INDIRECT("b2:b"&ROW($2:$6)),B$9),$C$2:$C$6),2,),按SHIFT+CTRL+ENTER键结束。df6 = pd.read_excel("test.xlsx", sheet_name='消费额')df6[df6['姓名'] == '张一'][['姓名', '消费额']]Out[]: 姓名 消费额0 张一 1002 张一 3004 张一 1000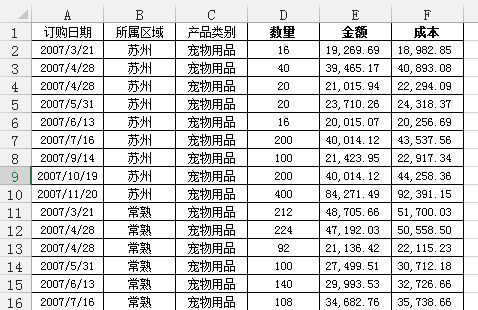
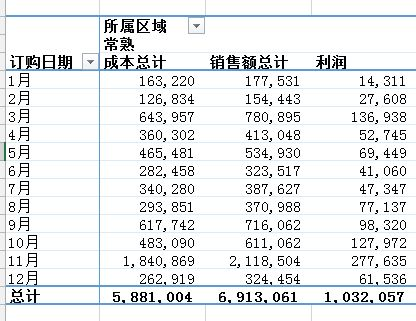
df = pd.read_excel('test.xlsx', sheet_name='销售统计表')df['订购月份'] = df['订购日期'].apply(lambda x:x.month)df2 = df.groupby(['订购月份', '所属区域'])[['销售额', '成本']].agg('sum')df2['利润'] = df2['销售额'] - df2['成本']df2
Out[]: 销售额 成本 利润订购月份 所属区域 1 南京 134313.61 94967.84 39345.77 常熟 177531.47 163220.07 14311.40 无锡 316418.09 231822.28 84595.81 昆山 159183.35 145403.32 13780.03 苏州 287253.99 238812.03 48441.962 南京 187129.13 138530.42 48598.71 常熟 154442.74 126834.37 27608.37 无锡 464012.20 376134.98 87877.22 昆山 102324.46 86244.52 16079.94 苏州 105940.34 91419.54 14520.80 ... ... ...11 南京 286329.88 221687.11 64642.77 常熟 2118503.54 1840868.53 277635.01 无锡 633915.41 536866.77 97048.64 昆山 351023.24 342420.18 8603.06 苏州 1269351.39 1144809.83 124541.5612 南京 894522.06 808959.32 85562.74 常熟 324454.49 262918.81 61535.68 无锡 1040127.19 856816.72 183310.48 昆山 1096212.75 951652.87 144559.87 苏州 347939.30 302154.25 45785.05
[]df3 = pd.pivot_table(df, values=['销售额', '成本'], index=['订购月份', '所属区域'] , aggfunc='sum')df3['利润'] = df3['销售额'] - df3['成本']df3
Out[]: 成本 销售额 利润订购月份 所属区域 1 南京 94967.84 134313.61 39345.77 常熟 163220.07 177531.47 14311.40 无锡 231822.28 316418.09 84595.81 昆山 145403.32 159183.35 13780.03 苏州 238812.03 287253.99 48441.962 南京 138530.42 187129.13 48598.71 常熟 126834.37 154442.74 27608.37 无锡 376134.98 464012.20 87877.22 昆山 86244.52 102324.46 16079.94 苏州 91419.54 105940.34 14520.80 ... ... ...11 南京 221687.11 286329.88 64642.77 常熟 1840868.53 2118503.54 277635.01 无锡 536866.77 633915.41 97048.64 昆山 342420.18 351023.24 8603.06 苏州 1144809.83 1269351.39 124541.5612 南京 808959.32 894522.06 85562.74 常熟 262918.81 324454.49 61535.68 无锡 856816.72 1040127.19 183310.48 昆山 951652.87 1096212.75 144559.87 苏州 302154.25 347939.30 45785.05
[60 rows x 3 columns]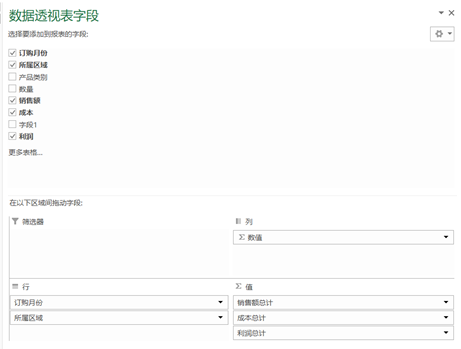
ins['weight'] = ins[['SK_ID_PREV', 'DAYS_ENTRY_PAYMENT']].groupby('SK_ID_PREV').apply(lambda x: 1-abs(x)/x.sum().abs()).iloc[:,1],1000万行的数据,足足算了十多分钟,等得我心力交瘁。import plotly.offline as offimport plotly.graph_objs as gooff.init_notebook_mode()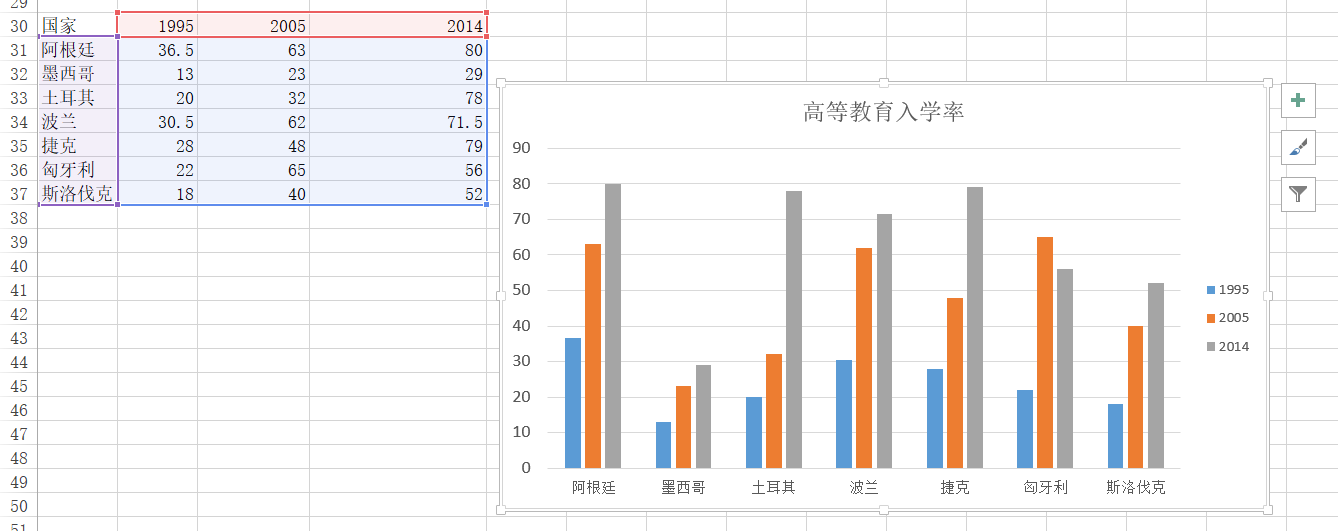
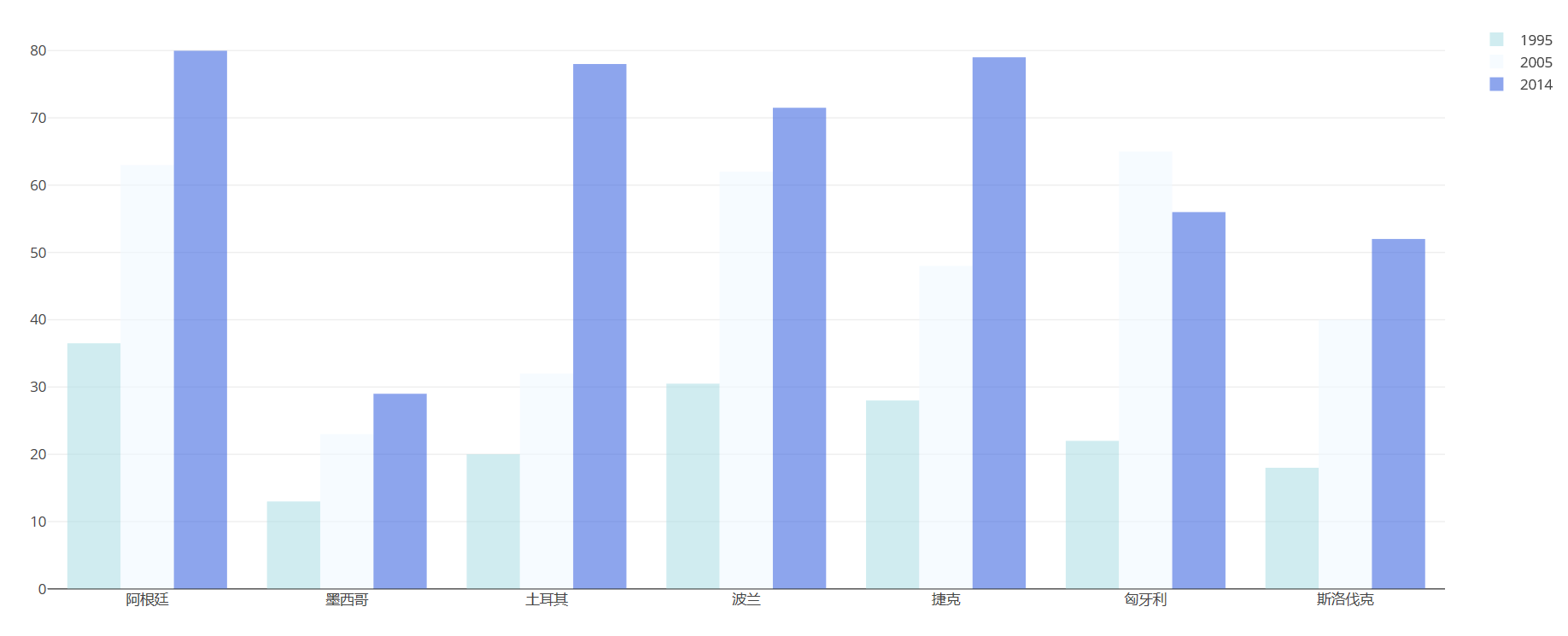
df = pd.read_excel("plot.xlsx", sheet_name='高等教育入学率')trace1 = go.Bar( x=df['国家'], y=df[1995], name='1995', opacity=0.6, marker=dict( color='powderblue' ) )
trace2 = go.Bar( x=df['国家'], y=df[2005], name='2005', opacity=0.6, marker=dict( color='aliceblue', ) )
trace3 = go.Bar( x=df['国家'], y=df[2014], name='2014', opacity=0.6, marker=dict( color='royalblue' ) )
layout = go.Layout(barmode='group')data = [trace1, trace2, trace3]fig = go.Figure(data, layout)off.plot(fig)
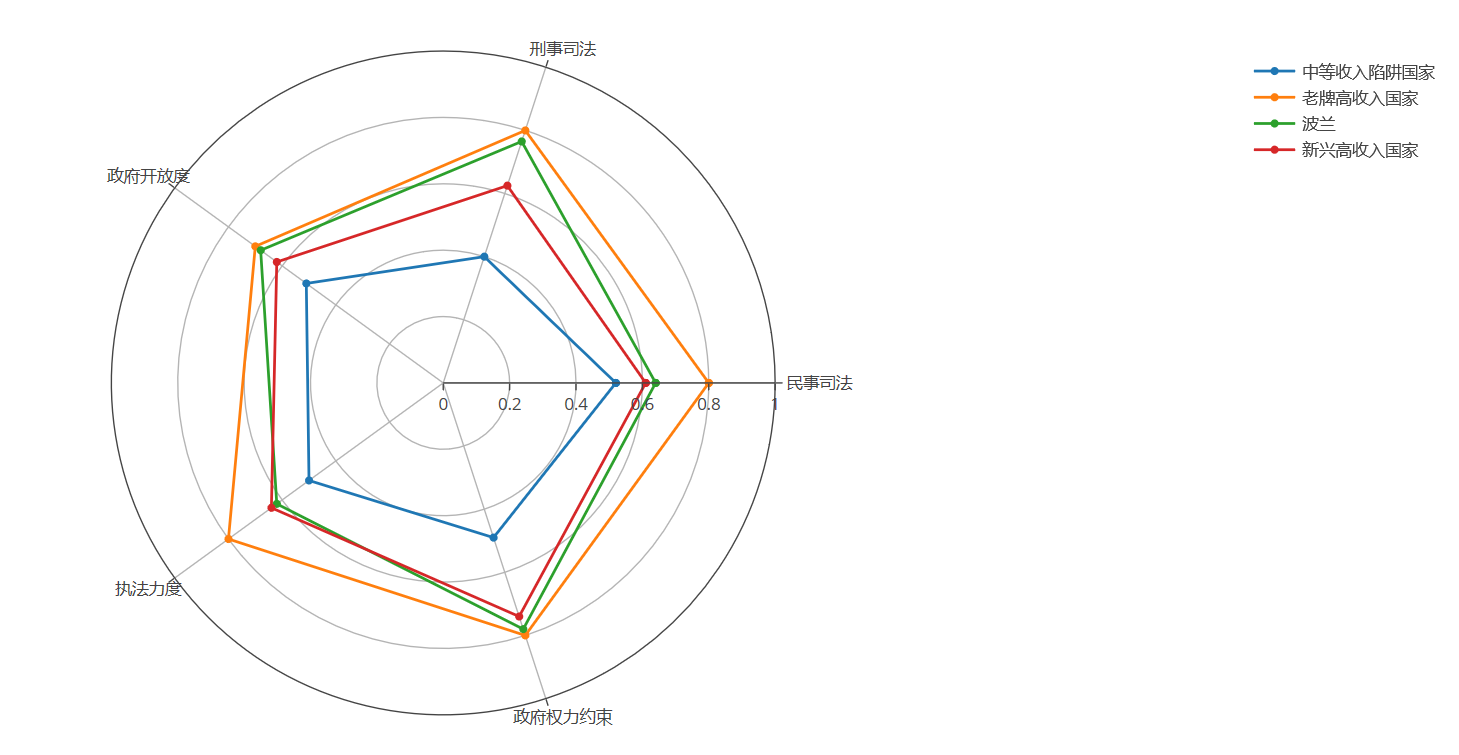
df = pd.read_excel('plot.xlsx', sheet_name='政治治理')theta = df.columns.tolist()theta.append(theta[0])names = df.index = df.iloc[:,0]df = np.array(df)
trace1 = go.Scatterpolar( r=df[0], theta=theta, name=names[0] )
trace2 = go.Scatterpolar( r=df[1], theta=theta, name=names[1] )
trace3 = go.Scatterpolar( r=df[2], theta=theta, name=names[2] )
trace4 = go.Scatterpolar( r=df[3], theta=theta, name=names[3] )
data = [trace1, trace2, trace3, trace4]layout = go.Layout( polar=dict( radialaxis=dict( visible=True, range=[0,1] ) ), showlegend=True )fig = go.Figure(data, layout)off.plot(fig)



